
Cellular network operators are struggling to increase network capacity by using the latest air interfaces, adopting the latest transmission frequencies, increasing bandwidth, and increasing the number of antennas and the number of cellular base stations, for which they need to significantly reduce equipment costs. In addition, operators need to increase equipment efficiency and network integration to reduce operating costs. To provide devices that meet these diverse needs, wireless infrastructure equipment manufacturers are looking for solutions with higher levels of integration, performance and flexibility with lower power and cost. In addition, equipment manufacturers are also reducing time-to-market while achieving these goals.
The key to reducing overall equipment costs is integration, but reducing operational costs requires advanced digital algorithms to improve power amplifier efficiency. One of the most commonly used algorithms is Digital Predistortion (DPD). Increasing device efficiency as device configurations become more complex is a challenge in itself. The radio transmission bandwidth is approaching 100 MHz with advanced Long Term Evolution (LTE-A) technology, and this number is even higher as vendors attempt to use multiple air interfaces in a discontinuous spectrum. At the same time, active antenna array (AAA) and remote radio unit (RRU) supporting MIMO also continuously put forward higher requirements on the computational bandwidth of the algorithm. In this article, we will examine how to use the Zynq-7000 All Programmable SoC (AP SoC) to improve the performance of current and future DPD systems, while providing device manufacturers with a low-cost, low-power solution with fully programmable features to help them Quickly introduce products to the market.
Implement cellular radio
The AP SoC uses a high-performance programmable logic (PL) architecture with serial transceivers (SERDES) and DSP blocks and a hardened processing subsystem (PS) that is tightly integrated with it. The processing subsystem also includes a dual-core ARM Cortex A9, floating point unit (FPU) and NEON media accelerator with UART, SPI, I2C, Ethernet and memory controllers necessary for complete radio operation and control. Peripherals. Unlike external general-purpose processors or DSP processors, because of the large number of connections between the PL and the PS, the interface between them requires extremely high bandwidth, which is not possible with a single solution. With these hardware/software combinations, the AP SoC device is capable of implementing all the functions required for the RRU on a single chip, as shown in Figure 1.
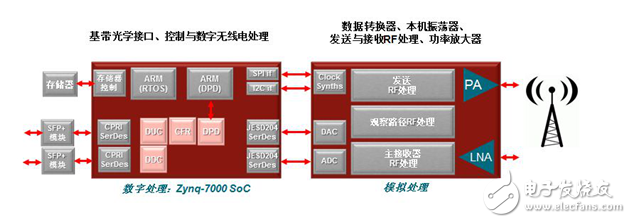
Figure 1. Typical radio infrastructure with all digital functions concentrated into a single device
The rich DSP resources in the PL can be used to implement digital signal processing functions such as digital up conversion (DUC), digital down conversion (DDC), crest factor reduction (CFR), and DPD. In addition, SERDES can support 9.8Gbps CPRI and 12.5Gbps JESD204B interfaces for connecting baseband converters and digitizers. PS supports symmetric multiprocessing (SMP) and asymmetric multiprocessing (AMP). In this case, assume that the AMP mode is used, and one of the ARM A9 processors is used to implement board-level control functions such as downlink messaging, scheduling, calibration, and alarms to run bare metal architectures, more likely operating systems such as Linux. The other processor is used to implement some of the required DPD algorithms, because not all parts of the algorithm support pure hardware solutions.
DPD can increase power amplifier efficiency by expanding the linear range. The drive to the amplifier is enhanced to improve the output power, thereby increasing efficiency while the static power consumption remains relatively constant. In order to expand the linear range, the DPD uses the analog feedback path of the amplifier and a large number of signal processing operations to calculate the coefficients (the coefficients are the reciprocal of the amplifier nonlinearity); then use these coefficients to pre-correct the transmitted power amplifier drive signal, and finally expand The purpose of the linear range of the amplifier.
The DPD algorithm can be decomposed into the following multiple functional blocks, as shown in FIG. 2.
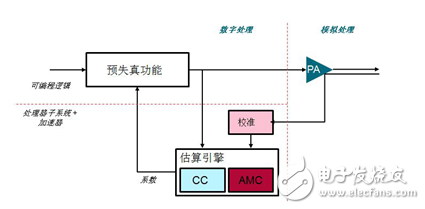
Figure 2. Digital predistortion is broken down into multiple functional areas
The DPD is a closed-loop system that captures the previously transmitted signal to determine the behavior of the amplifier based on the transmitted signal. The first task of the DPD is to calibrate the output of the amplifier with the previous transmit signal in an alignment block. The memory needs to be used to calibrate the data before starting any subsequent algorithm operations. Once the data is calibrated, the Autocorrelation Matrix Calculation (AMC) and Coefficient Calculation (CC) algorithms can be used to create coefficients that represent PA nonlinear reciprocal approximations; after the coefficients are obtained, the data path predistorter uses these data pairs to send to the PA. The signal is pre-corrected.
Accelerate DPD coefficient estimation
These features can be implemented in a number of different ways. Some functions are suitable for software, others are suitable for hardware, and others can be implemented by software or hardware, but ultimately, performance is used to determine which implementation. With AP SoC devices, designers can decide whether to implement hardware or software. For the DPD algorithm, the data path predistorter including the high-speed filtering function should be implemented in the PL due to the extremely high sampling rate, and the calibration engine and estimation engine used to generate the DPD coefficients can be in the ARM in the PS. Run on A9.
In order to determine whether software or hardware is used to implement the function, the software must first be characterized to determine its time-consuming situation. Figure 3 shows the software features of the DPD algorithm of Figure 2 for implementing three identifiable functions. According to the analysis results, 97% of the time in the Xilinx DPD algorithm is used for AMC processing, so the function is most accelerated first.
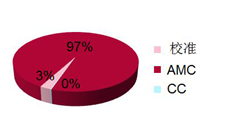
Figure 3. Characterization of software tasks in DPD processing
ARM A9 can be used to perform some additional functions, which also helps to improve the performance of such applications. For example, as part of the PS, each ARM A9 has a floating point unit and a NEON media accelerator. The NEON unit is a 128-bit single-instruction multi-data (SIMD) vector coprocessor that performs two 32x32b multiply operations simultaneously, making it ideal for AMC functions based on multiply-accumulate (MAC) operations. By leveraging the NEON module, you can take advantage of the software's inherent advantages, eliminating the need for low-level programming in assembly language.
Therefore, the use of additional features in the PS can significantly improve performance compared to soft processors such as Microblaze or external DSPs.
In order to further improve DPD performance, it is best to port these functions to the hardware using PL. However, the software is written in C or C++, and it takes some time to convert C or C++ into hardware that can run in a PL using VHDL or Verilog.
With the introduction of high-level synthesis (HLS) tools such as C-to-RTL, this issue has now been resolved. These tools allow programmers with C/C++ programming experience to perform hardware conversions in the form of FPGAs. Vivado HLS tools make it easy for designers and system architects to map C/C++ code to programmable logic for maximum code reuse, portability, and simple design space exploration to maximize productivity.
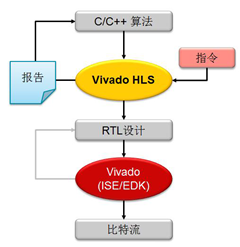
Figure 4. Vivado High Level Synthesis (HLS) design flow
Figure 4 shows a typical Vivado HLS high-level integrated design flow for C/C++. The tool's output is RTL and can be easily integrated with existing hardware designs, such as data path predistorters or upstream processing, and of course data converter interfaces.
This tool can be used to quickly port the algorithm to the hardware, where the algorithm must be connected to the PS via the AXI interface, as shown in Figure 5.
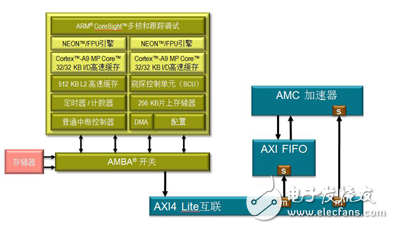
Figure 5. Integrating programmable logic-based AMC hardware accelerator algorithms with processing systems
Running the AMC algorithm at a high clock rate in the PL can significantly improve performance (as shown in Figure 6), achieving 70 times better performance than implementing the same functionality in software, and taking up less than 3% of APs. SoC device logic resources.
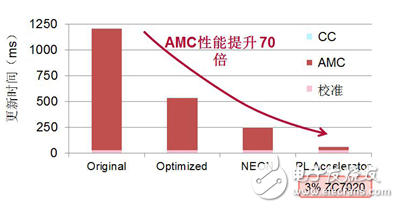
Figure 6. Performance comparison of pure software and hardware and software combined acceleration solutions
After a basic optimization of the original C/C++ reference code, the new code runs more efficiently on the ARM A9 processor, boosting the performance of the software-only implementation to at least two to three times the original code. At this point, enabling the NEON Media Coprocessor gives you additional performance benefits. The final result of Figure 6 is obtained by running the AMC algorithm in programmable logic (see Figure 5), which achieves an overall performance improvement of up to 70 times compared to the original software approach.
Ultimately, the radio performance defines the partition of the required DPD between hardware and software. The pursuit of higher levels of spectral correction can achieve greater efficiency, which can be a factor in performance. Achieving higher correction levels requires more processing power because of the increased accuracy for expressing amplifier nonlinearities. Other factors that affect performance are larger transmission bandwidth or sharing of estimation engines across multiple antennas. This approach requires only one processor plus an optional hardware accelerator to calculate coefficients for multiple data path predistorters, resulting in area (and cost) savings.
In some cases, the performance achieved by running software on an ARM A9 + NEON unit is sufficient, such as a narrowband transmission bandwidth configuration, or where only 1 or 2 antenna paths are required for data processing in the design. Reducing the area of ​​the radio configuration also reduces costs.
In order to further improve performance to the level above Figure 6, additional parallelism can be added to the implementation of the AMC function, but this requires an increase in logic implementation to reduce update time. In addition, a more in-depth analysis of the software may indicate other parts of the algorithm that can benefit from hardware acceleration. Whatever the requirements, today's tools and chips can help designers make trade-offs between performance, area, and power consumption in the pursuit of greater efficiency without having to be constrained by specific discrete devices or programming styles.
to sum up
The radio infrastructure requires low cost, low power consumption and high reliability, and integration is the key to achieving these goals, but until now it has not been possible without reducing flexibility or slowing down the market. In addition, broadband radio and the pursuit of greater efficiency are driving the need for processing. With a dual-core processor subsystem, high performance and low power programmable logic, the Zynq-7000 All Programmable SoC has become the solution to meet current and future radio needs.
Whether it's a remote radio or an active antenna array, designers can create products with greater productivity while achieving greater flexibility and performance than existing solutions such as ASSPs or ASICs. The boundaries between software and hardware are no longer clear, opening up endless possibilities for designers who need more advanced algorithms to differentiate their products.
Author: David Hawke, director of product marketing at Xilinx wireless market
Uv Sterilization Lamp,Uv Germicidal Lamp,Vehicle Uv Sterilization Lamp ,Portable Uv Disinfection Lamp
Ningbo Anbo United Electric Appliance Co.,ltd , https://www.airfryerfactory.com