
Hash, the general translation is "hash", and there is also a direct transliteration to "hash", which is to input an input of arbitrary length (also called pre-image) into a fixed-length output through a hash algorithm. The output is the hash value. This conversion is a compression map, that is, the space of the hash value is usually much smaller than the input space, and different inputs may be hashed to the same output, and it is not possible to uniquely determine the input value from the hash value. Simply put, it is a function that compresses messages of any length into a fixed-length message digest.
The hash table maps a set of keywords to a limited address range according to the set hash function H(key) and the processing conflict method, and stores the image in the address by the image of the keyword in the address range. Location, such a table is called a hash table or hash, and the resulting storage location is called a hash address or a hash address. As a linear data structure, compared with tables and queues, hash tables are undoubtedly a faster search.
A fixed-size result obtained by applying a one-way mathematical function (sometimes referred to as a "hash algorithm") to any amount of data. If there is a change in the input data, the hash will also change. Hash can be used for many operations, including authentication and digital signatures. Also known as the "message summary."
Simple explanation: Hash algorithm, which is a hash function. It is a one-way cryptosystem, that is, it is an irreversible mapping from plaintext to ciphertext. There is only an encryption process and no decryption process. At the same time, the hash function can change the input of any length to get a fixed length output. This one-way feature of the hash function and the fixed nature of the output data length allow it to generate messages or data.
(1) MD4
MD4 (RFC 1320) was designed by Ronald L. Rivest of MIT in 1990, and MD is an abbreviation of Message Digest. It is implemented on high-speed software on a 32-bit word processor - it is implemented based on bit operations of 32-bit operands.
(2) MD5
MD5 (RFC 1321) is an improved version of Rivest's MD4 in 1991. It still groups 512 bits for the input, and its output is a cascade of four 32-bit words, the same as MD4. MD5 is more complex than MD4 and is slower, but safer and performs better in terms of resistance to analysis and differential.
(3) SHA-1 and others
SHA1 is designed by NIST NSA to work with DSA. It produces a 160-bit hash value for inputs less than 264 in length, so it is better for brute-force. The SHA-1 design is based on the same principle as MD4 and mimics the algorithm.
Principles of common hash algorithmsThe hash table, which is designed based on the perspective of fast access, is also a typical "space-for-time" approach. As the name suggests, this data structure can be understood as a linear table, but the elements are not closely arranged, but there may be gaps.
A hash table (also called a hash table) is a data structure that is accessed directly based on a key value. That is, it accesses the record by mapping the key value to a location in the table to speed up the lookup. This mapping function is called a hash function, and the array that holds the records is called a hash table.
For example, we store 70 elements, but we may apply 100 elements of space for these 70 elements. 70/100=0.7, this number is called the load factor. The reason we do this is also for the purpose of "quick access." We arrange the storage locations for each element based on a fixed function H with a random average even distribution of results, so that linear search of ergodic properties can be avoided for fast access. However, due to this randomness, it is inevitable that one problem is conflict. The so-called conflict, that is, the two elements get the same address through the hash function H, then these two elements are called "synonyms". This is similar to 70 people going to a restaurant with 100 chairs for dinner. The result of the hash function is a storage unit address, and each storage unit is called a "bucket." To set a hash table with m buckets, the value range of the hash function should be [0, m-1].
Resolving conflicts is a complex issue.
The conflict mainly depends on:
(1) Hash function, the value of a good hash function should be distributed as evenly as possible.
(2) Handling conflict methods.
(3) The size of the load factor. Too big is not necessarily good, and the waste of space is serious, the load factor and the hash function are linked.
Ways to resolve conflicts:
(1) Linear exploration method: After the conflict, linearly test forward and find the nearest empty position. The downside is that there will be accumulation. When accessing, words that may not be synonymous are also located in the probe sequence, affecting efficiency.
(2) Double hash function method: After the position d conflicts, another hash function is used again to generate a number c which is mutually prime with the hash table bucket size m, and then try (d+n*c)%m to probe Sequence hopping distribution.
Common methods for constructing hash functions
Hash functions make access to a data sequence faster and more efficient, and through hash functions, data elements are positioned more quickly:
1. Direct addressing method: Take a linear function value of a keyword or keyword as a hash address. That is, H(key)=key or H(key) = a? Key + b, where a and b are constants (this hash function is called a self function)
2. Digital analysis: Analyze a set of data, such as the date of birth of a group of employees. At this time, we find that the first few digits of the date of birth are roughly the same, so that the probability of conflict will be great, but We found that the last few days of the year and month indicate that the numbers of the month and the specific date are very different. If the following numbers are used to form the hash address, the probability of conflict will be significantly reduced. Therefore, digital analysis is to find out the laws of numbers and use them as much as possible to construct hash addresses with low probability of collision.
3. Square method: Take the middle of the keyword squared as the hash address.
4. Folding method: The keyword is divided into several parts with the same number of digits, and the last part of the digits can be different, and then the superposition of these parts and the (removal of the carry) are taken as the hash address.
5. Random number method: Select a random function and take the random value of the keyword as the hash address, which is usually used when the keyword length is different.
6. In addition to the remainder method: the remainder of the keyword is divided by a number p that is not greater than the length m of the hash table table is the hash address. That is, H(key) = key MOD p, p "=m. Not only can the keyword be directly modulo, but also can be modulo after folding and squared. The choice of p is very important, generally taking prime or m, if p is not good, it is easy to produce synonyms.
Performance analysis
The hash table search process is basically the same as the table creation process. Some of the keys can be found directly through the address translated by the hash function. Other keys have conflicts at the address obtained by the hash function, and need to be searched in a way that handles conflicts. In the three methods of dealing with conflicts, the post-conflict lookup is still the process of comparing a given value with a key. Therefore, the measure of hash table lookup efficiency is still measured by the average lookup length.
During the search process, the number of comparisons of the key codes depends on how many conflicts occur, fewer conflicts are generated, the search efficiency is high, conflicts are generated, and the search efficiency is low. Therefore, the factors that influence the number of conflicts are the factors that affect the efficiency of the search. There are three factors that affect how conflicts occur:
1. Whether the hash function is uniform;
2. Methods of dealing with conflicts;
3. Fill factor for the hash table.
The fill factor of the hash table is defined as: α = the number of elements filled in the table / the length of the hash table
α is a flag factor for the degree to which the hash table is full. Since the length of the table is a fixed value, α is proportional to the number of elements in the table. Therefore, the larger α, the more elements are filled in the table, and the greater the possibility of conflict; the smaller α is, There are fewer elements populated into the table, and the less likely it is to have a conflict.
In fact, the average lookup length of the hash table is a function of the fill factor α, but different methods for handling conflicts have different functions.
Knowing the basic definition of hash, you can't help but mention some famous hash algorithms. MD5 and SHA-1 can be said to be the most widely used Hash algorithms, and they are all based on MD4. So what do they mean?
Here is a brief:
(1) MD4
MD4 (RFC 1320) was designed by Ronald L. Rivest of MIT in 1990, and MD is the abbreviation of Message Digest. It is implemented on high-speed software on a 32-bit word processor - it is implemented based on bit operations of 32-bit operands.
(2) MD5
MD5 (RFC 1321) is an improved version of Rivest's MD4 in 1991. It still groups 512 bits for the input, and its output is a cascade of four 32-bit words, the same as MD4. MD5 is more complicated than MD4, and it is slower, but safer and performs better in anti-analysis and anti-differential.
(3) SHA-1 and others
SHA1 is designed by NIST NSA to work with DSA. It produces a 160-bit hash value for inputs less than 264 in length, so it is better for brute-force. The SHA-1 design is based on the same principle as MD4 and mimics the algorithm.
The hash table inevitably collides: the same hash address may be obtained for different keywords, ie key1≠key2, and hash(key1)=hash(key2). Therefore, when building a hash table, you must not only set a good hash function, but also set a method to handle conflicts. The hash table can be described as follows: according to the set hash function H(key) and the selected processing conflict method, a set of keywords is mapped to a limited, address-contiguous address set (interval) and The "icon" of the keyword in the address set is stored in the table as the corresponding storage location. This table is called a hash table.
For dynamic lookup tables, 1) the table length is undefined; 2) when designing the lookup table, only the scope of the keyword is known, and the exact keyword is not known. Therefore, in general, a function relationship needs to be established, with f(key) as the key for the position of the key recorded in the table. Usually, this function f(key) is a hash function. (Note: this function is not necessarily a mathematical function)
A hash function is an image that maps a collection of keywords to a collection of addresses. Its settings are flexible, as long as the size of the collection does not exceed the allowable range.
In reality, the hash function needs to be constructed, and the construction is good enough to use.
So what is the use of these Hash algorithms?
The application of Hash algorithm in information security is mainly reflected in the following three aspects:
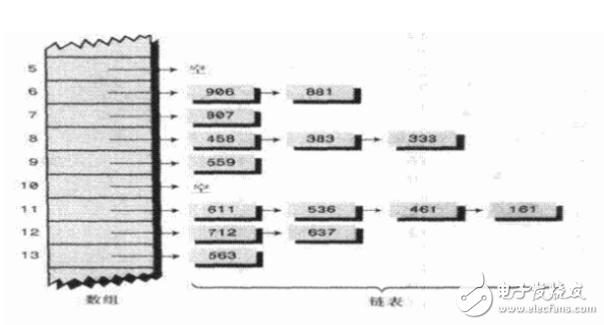
(1) Document verification
Our more familiar verification algorithms include parity check and CRC check. These two types of checksums do not have the ability to resist data tampering. They can detect and correct channel errors in data transmission to a certain extent, but they cannot prevent Malicious destruction of data.
The "digital fingerprint" feature of the MD5 Hash algorithm makes it the most widely used file integrity checksum (Checksum) algorithm. Many Unix systems provide commands for calculating the md5 checksum.
(2) Digital signature
The Hash algorithm is also an important part of the modern cryptosystem. Because of the slow operation speed of asymmetric algorithms, one-way hash functions play an important role in digital signature protocols. Digitally signing a hash value, also known as a "digital summary," is statistically equivalent to digitally signing the file itself. And such an agreement has other advantages.
(3) Authentication agreement
The following authentication protocol is also known as the challenge-authentication mode: this is a simple and secure method in the case where the transmission channel is audible but cannot be tampered with.
File hash value
The digital digest of the MD5-Hash-file is calculated by the Hash function. Regardless of the file length, its hash function evaluates to a fixed-length number. Unlike the encryption algorithm, this hash algorithm is an irreversible one-way function. With a highly secure Hash algorithm, such as MD5 and SHA, it is almost impossible for two different files to get the same hash result. Therefore, once the file is modified, it can be detected.
The Hash function has another meaning. The actual hash function refers to mapping a large range to a small range. The goal of mapping large areas to a small range is often to save space and make the data easy to store. In addition, hash functions are often applied to lookups. So, before considering the use of the Hash function, you need to understand a few of its limitations:
1. The main principle of Hash is to map a large range to a small range; therefore, the number of actual values ​​you enter must be equal to or smaller than the small range. Otherwise there will be a lot of conflicts.
2. Since Hash approaches a one-way function; you can use it to encrypt data.
3. Different applications have different requirements for the Hash function; for example, the hash function used for encryption mainly considers the gap between it and the single function, and the hash function used for lookup mainly considers the collision rate of its mapping to a small range.
The Hash function applied to encryption has been explored too much, and is described in more detail in the author's blog. Therefore, this article only explores the hash function used for lookups.
The main object of the Hash function application is an array (for example, a string), and its target is generally an int type. Below we will explain in this way.
In general, the Hash function can be easily divided into the following categories:
Addition Hash;
2. Bit operation Hash;
3. Multiplication Hash;
4. Division Hash;
5. Check the table Hash;
6. Mixed Hash;
GuangZhou HanFong New Energy Technology Co. , Ltd. , https://www.gzinverter.com