
The embedded computer vision system is very similar to the human visual system, analyzing and extracting video information from a wide variety of products to perform the same visual functions as the human visual system.
In embedded portable products such as smartphones, digital cameras and camcorders, high performance must be provided with limited size, cost and power consumption. The emerging market for high-volume embedded vision products includes automotive security, surveillance and gaming. Computer vision algorithms identify objects in the scene and then produce an image area that is more important than other image areas. For example, object and face detection can be used to enhance video conferencing experiences, public safety archive management, and content-based retrieval and many other aspects.
Cropping and resizing can be done to properly place the image at the center of the face. In this paper, we present an application for detecting a face in a digital image, cropping the selected main face, and resizing the image to a fixed size output image (see Figure 1). This application can be used on a single image or on a video stream and is designed to run in real time. As long as people pay attention to real-time face detection on mobile products, in order to achieve real-time throughput, appropriate execution steps must be taken.
This paper presents deployment steps for performing real-time face detection applications on a programmable vector processor that can be used to perform similar computer vision algorithms on any mobile product, in which case they are generic.

Figure 1: CEVA Face Detection Application
Although still image processing consumes a small amount of bandwidth and allocates memory, video is quite demanding on current memory systems.
On the other hand, the memory system design of computer vision algorithms is extremely challenging due to the need for more processing steps to detect and distinguish objects. Consider a 19x19 pixel size facial graphic thumbnail. For this small image, there are 256,361 possible combinations of gray values, which require extremely high three-dimensional space. Due to the complexity of facial images, it is difficult to clearly describe facial features; therefore, other methods based on statistical models have been established. These methods treat the face area as a graph, construct a discriminator by aiming at many "face" and "non-face" samples, and then determine whether the image contains a human face by analyzing the graph of the detected area.
Other challenges that face detection algorithms must overcome are: posture (front, 45 degrees, side, inversion), presence or absence of structural parts (whiskers, glasses), facial expressions, occlusion (some faces may be covered by other objects), image orientation (In the direction of rotation of the camera's optical axis, the surface of the face changes directly) and imaging conditions (illumination, camera characteristics, resolution).
Although many face detection algorithms have been introduced in the literature, only a small number of algorithms can meet the real-time limitations of mobile products. Although many face detection algorithms are reported to produce high detection rates, few algorithms are suitable for real-time deployment on these mobile products due to computational and memory limitations of mobile products such as mobile phones.
Typically, real-time execution of face detection algorithms is performed on PCs with relatively powerful CPUs and large memory sizes. An examination of existing face detection products shows that the algorithms introduced by Viola and Jones in 2001 have been widely adopted. This is a groundbreaking work that allows for a real-time approach based on a look-and-feel approach while maintaining the same or higher accuracy.
This algorithm utilizes an enhanced cascade of simple features and can be divided into three main parts: (1) integral graph - efficient convolution for fast feature evaluation; (2) use of Adaboost for feature selection, and according to importance They are screened by sex order. Each feature can be used as a simple (weak) discriminator; (3) Adaboost is used to understand the cascade distinguisher (a set of weak discriminators) that filters out areas that are least likely to contain faces. 2 is a schematic diagram of a classifier cascade. In an image, most sub-images are not face instances.
Based on this assumption, we can use a smaller efficient classifier to exclude many negatives at an early stage, while detecting almost all positive cases. In the later stages, more complex distinguishers were used to review the difficult situation.
Example: 24 cascade categorizer
Level 1 feature distinguisher => Exclude 60% non-facial while detecting 100% face
Secondary 5 feature distinguisher => Exclude 80% non-face, while detecting 100% face
Level 3, Level 4 and Level 5 20 feature distinguishers
Level 6 and Level 7 50 feature distinguishers
Level 8 to 12 100 feature distinguishers
Level 13 to 24 200 feature distinguisher
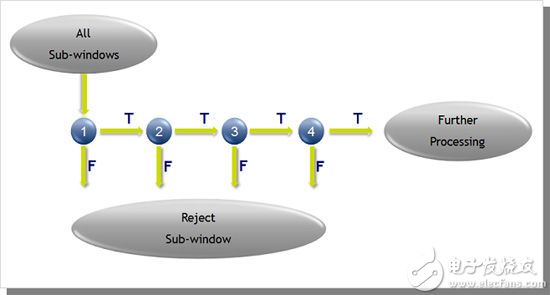
Figure 2: Cascading of the divider
At the first level of the face detection algorithm, rectangular features can be quickly calculated using an intermediate representation called an integral image. As shown in FIG. 3, the integral image value of the point (x, y) is the sum of all the pixels of the upper and left portions. The sum of the pixels in D can be calculated as 4+1-(2+3).

Figure 3: Rapid evaluation of rectangular features using integral images
In order to perform real-time face detection applications on embedded products, advanced parallelism combining instruction level parallelism with data level parallelism is required. The Very Long Instruction Word (VLIW) architecture enables advanced parallel instruction processing, providing extended parallelism and low power consumption.
The Single Instruction Multiple Data (SIMD) architecture enables single instructions to be run on multiple data elements, reducing code length and performance. Using the vector processor architecture, the calculation of these integral sums can be accelerated by the adder/subtractor parallel quantity factor. If the vector register can load 16 pixels and these pixels can be added to the next vector at the same time, the acceleration factor is 16. Obviously, adding a similar vector processing unit to the processor can double this factor.
In the next face detection phase, images are scanned at multiple locations and at multiple scales. Adaboost's powerful distinguisher (a distinguisher based on a rectangular feature) is used to determine if the search window contains a face. Again, vector processors have the obvious advantage of having the ability to simultaneously compare multiple position data to thresholds.
Suppose that in an image, most of the sub-images are not facial examples. The more parallel comparators that can be provided, the faster the acceleration.
For example, if the architectural design has the ability to compare two of the eight elements in one cycle, then it takes only one cycle to exclude the sub-images of the 16 positions. To simplify data loading and efficiently utilize vector processor loading/storing, the various locations can be spatially close to each other.
In order to achieve highly parallel code, the architecture should support instruction prediction. This allows the branches resulting from the if-then-else construct to be replaced with sequential codes, thereby reducing the number of loops and shortening the code length. Allows conditional execution, the ability to combine various conditions, and achieve greater efficiency in control code. In addition, non-sequential codes, such as branches and loops, are designed to have zero cycle loss without the need for cumbersome techniques such as dynamic branch prediction and inferential execution that increases the power loss of the RISC processor.
A key application challenge is memory bandwidth, which requires scanning each frame of video to perform face detection. Due to its large amount of data, video streams cannot be stored in Tightly Coupled Memory (TCM). For example, a YUV 4:2:0 format HD frame occupies 3MB of data memory. This high memory bandwidth results in higher power losses and requires more expensive DDR memory, making bill of materials more expensive. A perfect solution is to use data tiling to store pixels. The 2-dimensional data block is accessed by DDR in a single burst, which greatly improves the efficiency of DDR. Direct Memory Access (DMA) transfers data between external memory and core memory subsystems. In the final face detection application phase, the sub-image size including the detected face is re-adjusted to the fixed size output window.
The image resizing process is also used during the detection phase when the image is scanned in multiple scales. Size adjustment algorithms are widely used in image processing for video magnification and reduction. The algorithm executed in the face detection application is a bicubic algorithm. The cubic convolution interpolation determines the gray value based on the weighted average of the 16 pixels closest to the specified input coordinates, and assigns the value to the output coordinates. First, four one-dimensional cubic convolutions are performed in one direction (horizontal direction), and then more one-dimensional cubic convolutions are performed in the vertical direction. This means that a two-dimensional cubic convolution is performed, and what is needed is a one-dimensional cubic convolution.
The vector processor core has powerful load-and-storage capabilities, and the ability to access data quickly and efficiently is a key feature of such applications, where the algorithm runs on the data block. Sizing algorithm optimization can be satisfied by accessing a 2-dimensional memory block from memory in a single loop.
This feature enables the processor to efficiently implement higher memory bandwidth without the need to load unnecessary data or load computing units that perform data operations. In addition, data can be transposed during data access without any loop loss, which allows transposed blocks to be accessed in a single loop, which is very practical for performing horizontal and vertical filtering. The power of the processor is the result of its ability to perform powerful convolution, and parallel filters can be executed in a single loop.
Here is an example of an effective solution. The 4x8 byte block is loaded in one loop, then each iteration utilizes 4 pixels and the convolution is performed in the vertical direction. These 4 pixels are pre-arranged in 4 separate vector registers, so we can get 8 results at the same time. These intermediate results are then processed exactly at the same time, but the data is loaded in a transposed format to complete the horizontal filtering. In order to maintain the accuracy of the results, it is necessary to initialize the results with rounding values ​​and post-shifts. The filter configuration should implement these features without requiring special instructions.
In summary, this parallel vector processing solution core balances load/store unit operations and processing units. In general, data bandwidth limitations and the cost of processing units in terms of power consumption and die area limit execution efficiency; however, it is clear that significant acceleration of the scalar processor architecture can be achieved.
Multi-purpose programmable HD video and imaging platform for multimedia devices
The CEVA-MM3000 is a scalable, fully programmable multimedia platform that can be integrated into SoCs to provide 1080p 60fps video decoding and encoding, ISP functions and vision applications in full software. The platform consists of two dedicated processors, a stream processor and a vector processor, integrated into a complete multi-core system, including local and shared memory, peripherals, DMA, and standard bridges to external buses. This comprehensive multi-core platform is designed to meet the low power requirements of mobile products and other consumer electronics.
The vector processor includes two independent vector processing units (VPUs). The VPU is responsible for all vector calculations, including inter-vector operations (using single instruction multiple data streams) and vector internal operations. Inter-vector instructions can run on 16 8-bit (bytes) or 8 16-bit (word) elements, and vector register pairs can be used to form 32-bit (double word) elements. The VPU has the ability to complete 8 parallel filters (taps) in 6 lines (taps) in a single cycle.
Although the VPU is the computational main force of the vector processor, the vector loading and storage unit (VLSU) acts as a tool for transferring data from the data memory subsystem to the vector processor and from the vector processor to the data memory subsystem. The VLSU has 256-bit bandwidth for load and store operations and supports non-aligned access. The VLSU is equipped with the ability to access two-dimensional data blocks in a single loop and supports different data block sizes.
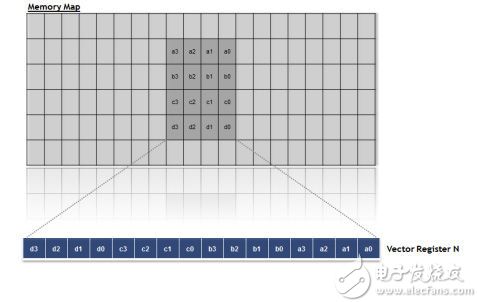
Figure 4: Loading a 4x4 pixel block
To simplify the VPU task, the VLSU has the flexibility to manipulate the data structure while reading/writing the vector registers. During data access, the data block can be transposed without any loop loss, enabling access to the transposed data block in a single loop. The transpose function can be dynamically set or cleared. In this way, the horizontal filter and the vertical filter can reuse the same function, saving development and debugging time for each filter while reducing the footprint of the program memory.
in conclusion
For consumer products using the CEVA-MM3000 platform, embedded vision applications are an example of the efficient implementation of algorithmic diversity, such as face detection with cropping and resizing. According to forecasts, similar and more complex application requirements will grow in the future, all of which can take advantage of the programmability and scalability of the CEVA-MM3000 architecture.
5050 Single Color Led Strip ,Single Color Led Strip,Single Color Led Strip Lights,Single Colour Led Strip
NINGBO SENTU ART AND CRAFT CO.,LTD. , https://www.lightworld-sentu.com