
This article mainly analyzes the following two points:
1. MapReduce job running process principle
2. The process of Shuffle and sorting in Map and Reduce tasks
The following is a schematic diagram of the MapReduce process drawn by visio2010:
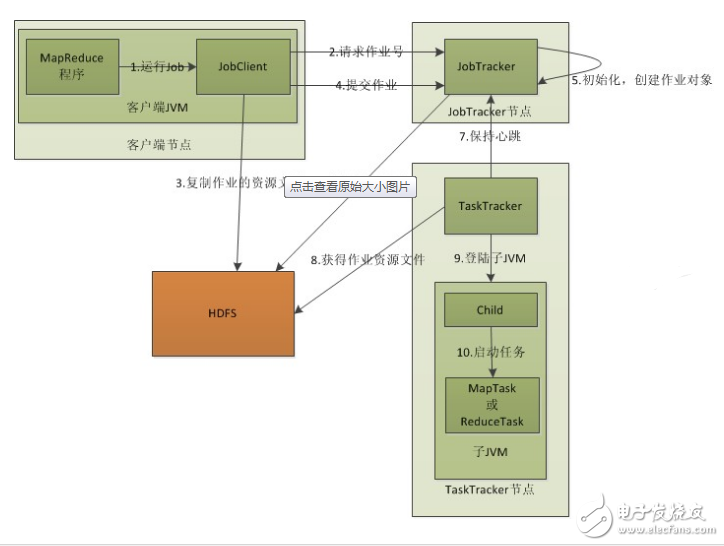
Process analysis:
1. Start a job on the client.
2. Request a Job ID from the JobTracker.
3. Copy the resource files needed to run the job to HDFS, including the JAR file packaged by the MapReduce program, the configuration file, and the input partition information calculated by the client. These files are stored in the folder that JobTracker created specifically for the job. The folder is named the Job ID of the job. The JAR file will have 10 copies by default (mapred.submit.replicaTIon attribute control); the input split information tells the JobTracker how many map tasks should be started for this job.
4. After the JobTracker receives the job, it is placed in a job queue, waiting for the job scheduler to dispatch it (this is not very similar to the process scheduling in the microcomputer, huh, huh), when the job scheduler is based on its own scheduling algorithm When scheduling to the job, a map task is created for each partition based on the input partition information, and the map task is assigned to the TaskTracker for execution. For map and reduce tasks, the TaskTracker has a fixed number of map slots and reduce slots depending on the number of host cores and the size of the memory. The important thing to emphasize here is that the map task is not easily assigned to a TaskTracker. Here is a concept called Data-Local. This means that the map task is assigned to the TaskTracker containing the data block processed by the map, and the program JAR package is copied to the TaskTracker to run. This is called "operational movement, data does not move". Data localization is not considered when assigning reduce tasks.
5. TaskTracker sends a heartbeat to the JobTracker every once in a while, telling the JobTracker that it is still running, and the heartbeat also carries a lot of information, such as the progress of the current map task completion. When the JobTracker receives the last task completion message for the job, it sets the job to "success". When the JobClient queries the status, it will know that the task is complete and a message is displayed to the user.
The above is to analyze the working principle of MapReduce at the level of client, JobTracker and TaskTracker. Let's take a closer look at the analysis of the map task and reduce task level.
Shuffle and sorting process in Map and Reduce tasksAlso post the flow diagram I drew in visio:
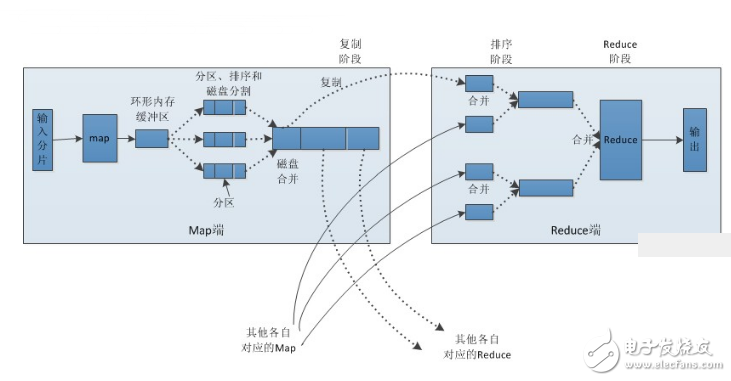
Process analysis:
Map side:
1. Each input fragment will be processed by a map task. By default, the size of one block of HDFS (default is 64M) is a slice. Of course, we can also set the size of the block. The result of the map output will be temporarily placed in a ring memory buffer (the size of the buffer is 100M by default, controlled by the io.sort.mb property), when the buffer is about to overflow (default is 80% of the buffer size) , controlled by the io.sort.spill.percent property), creates an overflow file in the local file system and writes the data from this buffer to this file.
2. Before writing to the disk, the thread first divides the data into the same number of partitions according to the number of reduce tasks, that is, a reduce task corresponds to the data of one partition. This is done to avoid some reduce tasks assigned to a large amount of data, while some reduce tasks are divided into very few data, even without the data to the embarrassing situation. In fact, partitioning is the process of hashing data. Then sort the data in each partition. If Combiner is set at this time, the sorted result will be Combia. The purpose of this is to write as little data as possible to disk.
3. When the map task outputs the last record, there may be a lot of overflow files, and you need to merge these files. During the merging process, sorting and combia operations are continually performed for two purposes: 1. Minimize the amount of data written to the disk each time; 2. Minimize the amount of data transmitted by the network during the next replication phase. Finally merged into a partitioned and sorted file. In order to reduce the amount of data transmitted over the network, you can compress the data here, just set mapred.compress.map.out to true.
4. Copy the data in the partition to the corresponding reduce task. Someone may ask: How does the data in the partition know which reduce is corresponding to it? In fact, the map task has been in constant contact with its parent TaskTracker, and TaskTracker has been keeping heartbeat with the JobTracker. So the MacroTracker saves the macro information in the entire cluster. As long as the reduce task gets the corresponding map output location from the JobTracker, it is ok.
At this point, the map end is analyzed. So what exactly is Shuffle? Shuffle Chinese means "shuffle". If we look at it like this: the data generated by a map is distributed to different reduce tasks through the hash process partition. Is it a process of shuffling the data?
Reduce side:
1. Reduce will receive data from different map tasks, and the data from each map is ordered. If the amount of data accepted by the reduce side is quite small, it is stored directly in memory (the buffer size is controlled by the mapred.job.shuffle.input.buffer.percent property, indicating the percentage of heap space used for this purpose), if the amount of data Exceeding a certain percentage of the buffer size (determined by mapred.job.shuffle.merge.percent), the data is merged and written to disk.
2. As the number of overflow files increases, the background thread merges them into a larger, ordered file, in order to save time for subsequent merges. In fact, whether on the map side or the reduce side, MapReduce repeatedly performs sorting and merging operations. Now I finally understand why some people say that sorting is the soul of hadoop.
3. During the merge process, many intermediate files (written to disk) will be generated, but MapReduce will make the data written to the disk as small as possible, and the result of the last merge is not written to the disk, but directly input to the reduce function. .
Board To Board Connector,2.54Mm Pitch Board To Board Connector,0.635Mm Floating Board To Board Connector,Board To Board Female Socket Connector
Shenzhen Hongyian Electronics Co., Ltd. , https://www.hongyiancon.com